Two steps towards a modern data platform
When building Data Science products, an important aspect is getting your data available and ready to use. You’ll need a platform to bring data together and serve it across the company. But how do you go about developing such a data platform? It’s easy to get lost when reading about Data Warehouses, Data Lakes, Lakehouses and Data Meshes. How are they different, and what should be the first steps?
Different data platform solutions
Data platforms are environments that bring data together and serve it across the company. The Data Warehouses were the first enterprise central data platforms. However, with a growing variety of data formats and sources, they weren’t flexible enough. The Data Lake was introduced to easily allow storage of raw data, in any format, from any source. This is made possible by postponing schema creation and data interpretation until data is actually being used. These lakes often turned in so-called Data Swamps, where no one could really use the data efficiently. All data was added, but no data was being prepared for usage. The successor is the Lakehouse, where a Data Lake is combined with database tooling to easily create usable views of the data. An alternative is the Data Mesh, which doesn’t centralize the data, but utilizes multiple decentralized data environments to better scale across teams. I’ll cover the Data Mesh more thoroughly later.
But first, let’s see what problem we are actually solving. What is the driver for these different data platforms? I’ll start with the utopian ideal we are chasing, continue with the platforms emerging in practice, and wrap up with two steps you can take. Two steps in the direction of a data platform that enable machine learning solutions, empower data scientists, and share the internal way of working.
The utopian ideal
Wouldn’t it be great if all data, from all departments, were easily accessible. Accessible from one central location, such that all your data scientists can get the data they need, whenever they need. They can focus on advanced machine learning, while data engineers ensure the data is ready to use.
Let’s meet Jane, our expert data scientist. She is developing a new data science product: revenue forecasts. All data on customers, products, and sales is available in the central data platform. Jane constructs the full dataset in the platform and loads it in her Jupyter Lab environment. After a bit of alignment with the business about the goal of the model, she quickly develops a first version of the model.
The platform thus provides everything the scientist needs to develop her model, including data, computing and working environments. The platform developers (cloud and data engineers) ensure it is scalable, real-time and performant. They also provides additional services like data-lineage, data governance, and meta data. The scientists are fully empowered and relieved of engineering difficulties. This is represented visually as follows:
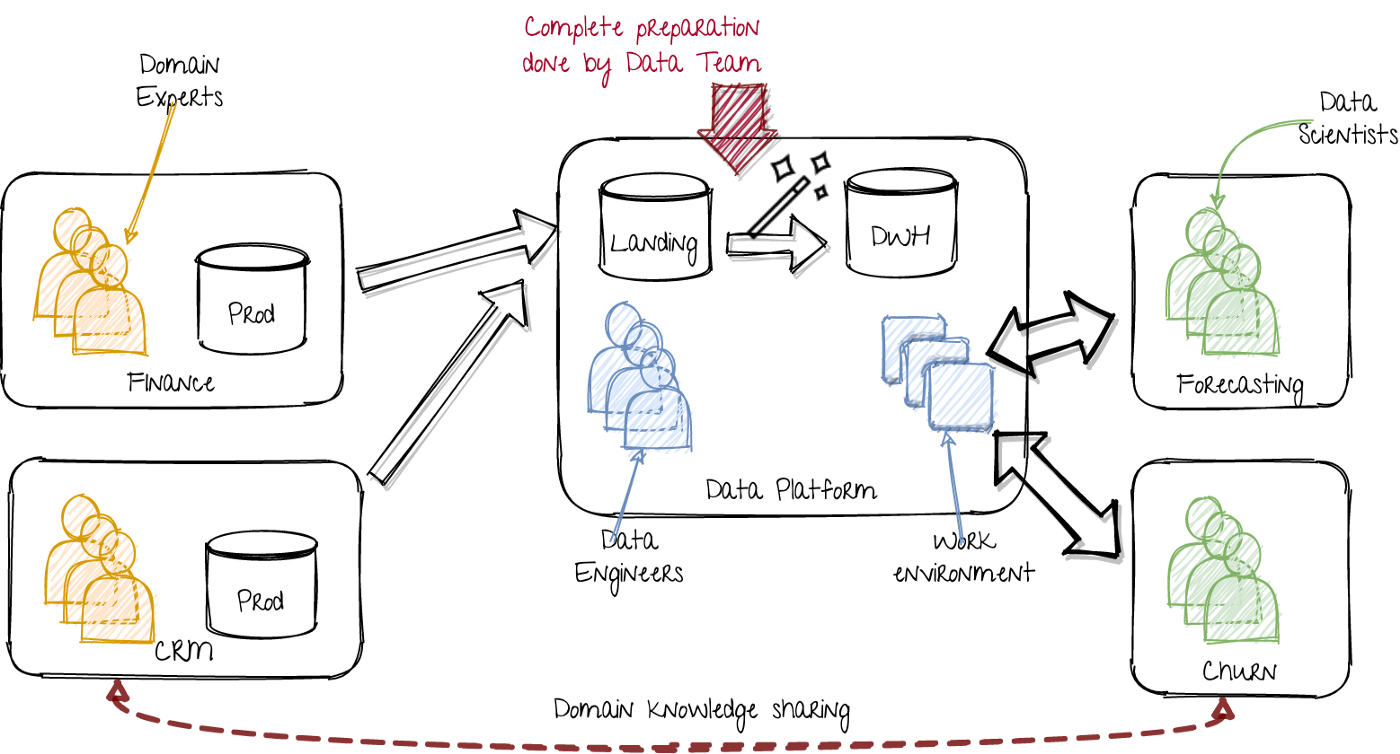
Utopian world: Single data platform taking care of all the data issues. Image by author.
On the left, the various departments run their applications with corresponding data. In a tech product company, this includes the teams working on specific domains. The data can live in any storage: MS Excel files, databases, csv files, Kafka topics, cloud buckets, you name it.
In the middle, the data platform team extracts that data, and loads it into the landing zone of their data lake. The first step is to standardize aspects like date and number formats and column names. This can include taking snapshots of data for historical views. The resulting collection of datasets is stored in a so-called ‘staging’ layer. The data is then combined and placed in the curated layer. The curated layer is a data storage that contains coherent datasets, unique identifiers and clear relations. I therefore refer to this as DWH (Data Warehouse). However, it can be any usable storage, including large scale cloud databases (BigQuery), Hive tables, blob storage (S3) or Delta Lake parquet files. The goal of this curated layer is to provide an easy to use total view of all the data.
On the right, the data science teams use the platform’s work environments and datasets to solve their use cases.
When this doesn’t work
That ideal sounds great. Unfortunately, Jane’s real experience was slightly different:
Jane needed some extra datasets to be made available on the data platform. To get a head start, the finance department provided some CSV exports for preliminary analysis. Jane discovers that the forecasts need to be reported on product groups, while the data is on individual products. After a few meetings she learns which internal product names belong to which groups. The revenue on products is separated in components, partly to base offerings, partly to add-ons. Discounts are another story; because they are subtracted from the total bill, the attribution becomes a bit tricky. Another surprise. Three months ago the public offerings got refreshed, renaming and combining some of the old niche products. With some difficulty and only dropping minimal data, she manages to match the the old data to most similar new products.
How about the data engineers managing the data platform? Well, they are just getting started:
At last, the data engineering ticket is picked up, and the data engineers start to extract, load and transform the various data-sets. The first steps are easy, but now they need to create usable views on the data. They need to talk to various (possible) future users to know which transformations are important. They organize some refinement meetings with, among others, Jane. Then they need to go back to the data producing departments to figure out what the data actually means, and how it maps to their domain. The department is too busy with some new internal products. They therefore forward the data engineers to a data science team, which apparently already has done some preparation work.
In short, this is not going very smoothly.
There are a few key issues:
- Data scientists need to be able to create use case specific transformations.
- The platform team needs to prepare data of a domain they don’t own, to facilitate use cases they aren’t working on.
- The data platform team becomes a bottleneck for data scientist teams.
The resulting workaround
To be able to interpret and transform highly detailed data related to a specific use case, you need a lot of domain knowledge. Each use case also requires specific data preparation. The data engineers can thus only do part of what the data scientists require. While the data scientists dive deep into the business case, they gain a lot of domain knowledge. This enables them to prepare the data.
This results in the following workaround situation:
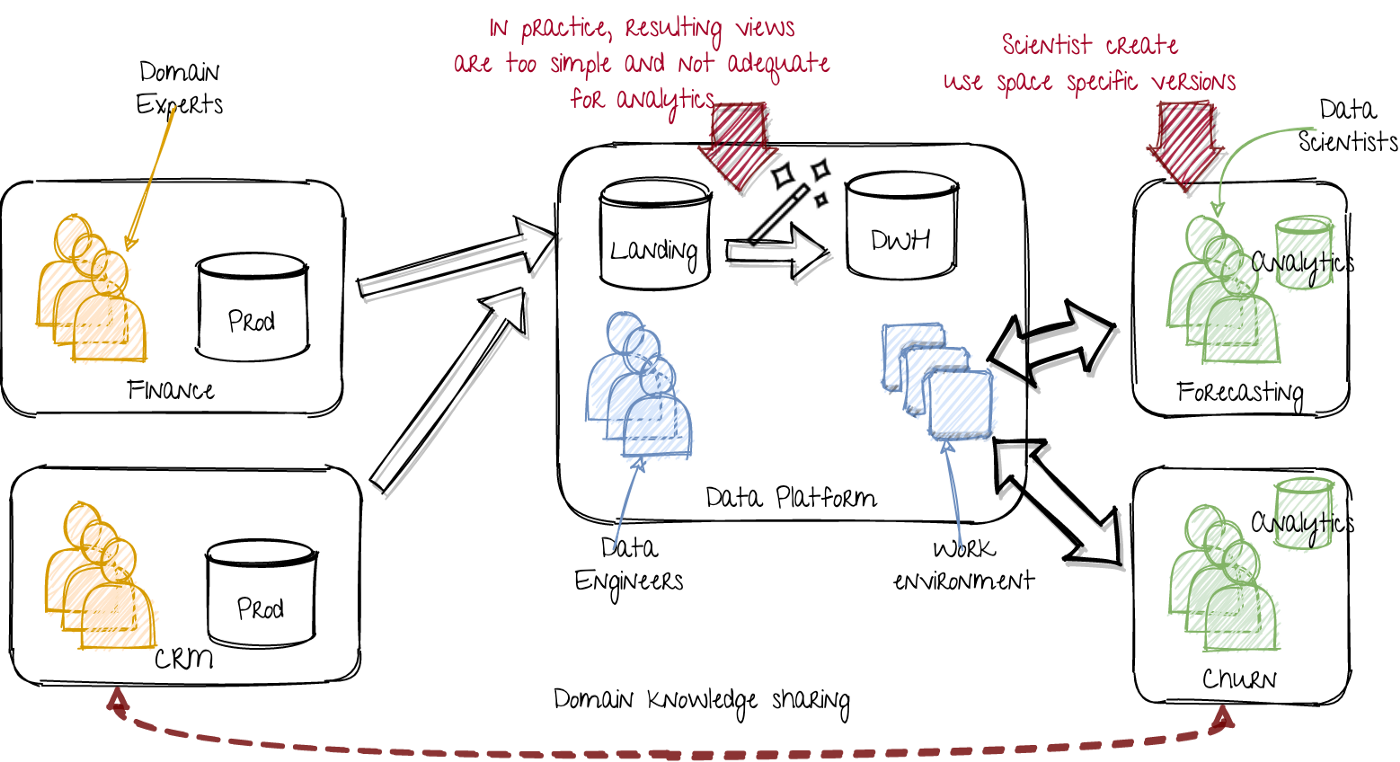
Extra data storage within the data science teams. Image by author.
The data science teams now transform data from the central data platform as preparation for their model training. Even though the data platform ideally provides a fully usable data-set, in practice it is too simple and not adequate enough for all their customers.
This new situation has some benefits:
- Data scientists become more self sufficient.
- The data engineers don’t have to create views for everyone in the organization. They can focus on standardized interfaces to the data.
- The data engineers can focus on keeping the data recent and providing good methods of access.
However, some things still are going wrong:
- The data scientists’ data sets and their producing pipelines don’t have the same standards as the data platform. They aren’t monitored that well, aren’t resilient to failures, and task scheduling isn’t standardized.
- With more decentralized transformations, multiple data science teams are reinventing the proverbial wheel.
The new ideal: the Data Mesh
A while ago the concept of Data Mesh has emerged (see this interesting blog post, and this followup). Data originates from multiple places in an organization. Instead of creating a single representation of all combined data, the data mesh accepts the decentralized nature of data. To still make the data company wide available, each team’s data is also regarded as a product of that team. The teams in the company also take care of creating usable views of their data. In this case, the machine learning (ML) product teams (the data scientists) would also deliver their transformed data as a product to other data scientists. They get their own data from various other product teams. Each product team (or group of teams) thus not only develops their product, but also provides usable views to other teams. Before I explain what the advantages are, let me draw the new situation:
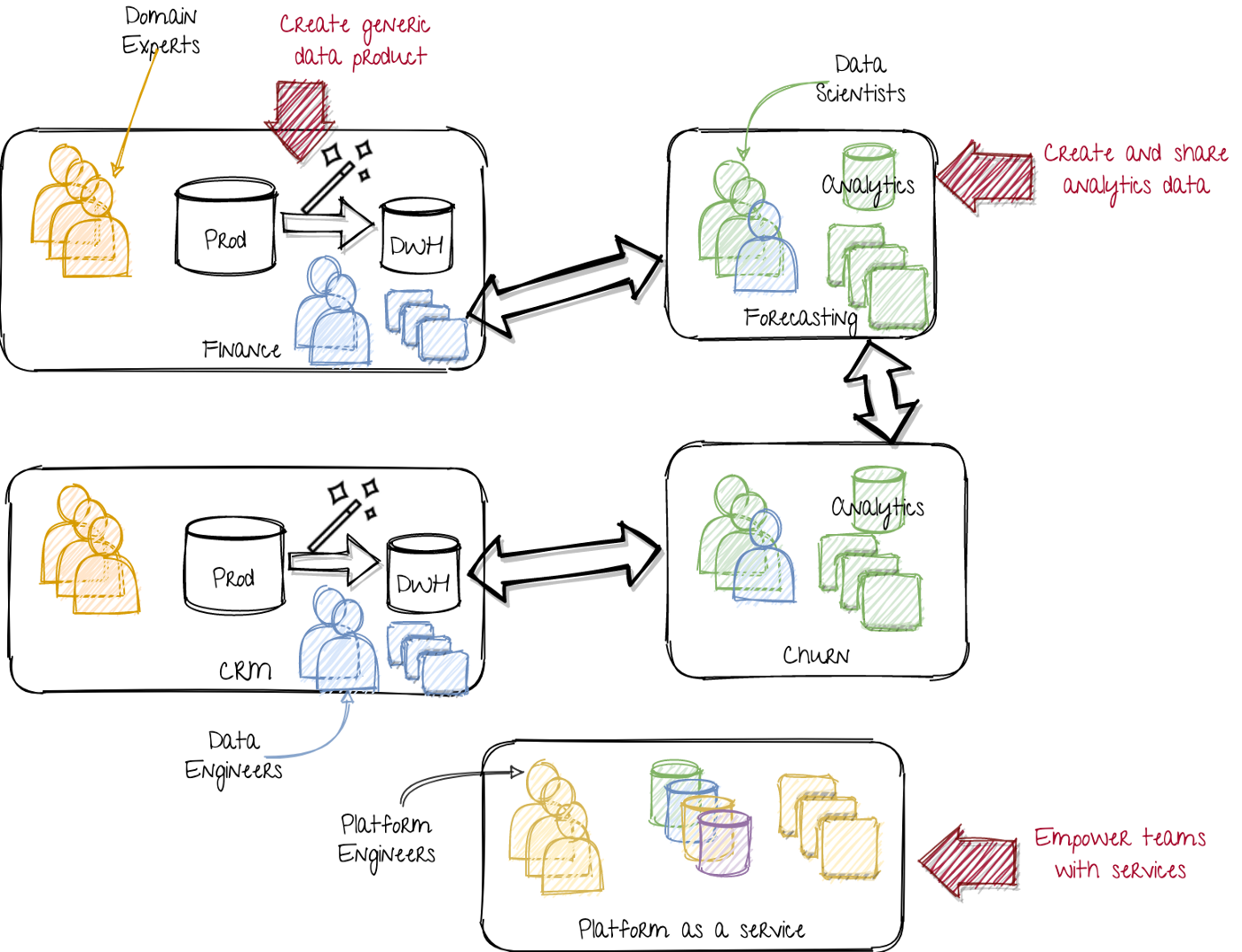
A data mesh approach. Image by author.
On the left, the departments or product teams provide the generic data as a service. While a set of normalized tables (DWH) is one possibility, it could also include event streams (Kafka) or blob storage. This requires more data engineering capabilities in the product teams. Instead of a central team with al the data engineers, the data engineers are now spread across all the product teams, including the analytics and ML teams.
In the middle, the central data platform has changed from a data product team (requiring domain knowledge) into a data platform as a service team (requiring technical knowledge). They develop in-house platforms, empowering all teams to create their own instances for data stores, feature stores, data processing, data lineage, scheduling, process monitoring, model artifacts, model serving instances, and so on. Thus all the technology skills from the previous data platform team are used to create tools. That way every team can become their own (small scale) data platform team. This ensures a uniform way of working and high standards across the whole company.
On the right, the data science teams are not only consumers of data, but also producers of data. The results of their feature engineering and data mangling is shared with other data science teams.
This has quite some benefits:
- Transformations are created where the domain knowledge is.
- The data platform team bottleneck is removed.
- Self sufficient product teams.
The challenges are:
- Setting up a central platform as a service team.
- Preventing the new central data platform as a service team of becoming the new bottleneck.
- Getting all teams on board of this new approach in a shared way of working.
In this setup the central platform as a service team (or teams) has a key role. They setup and provide infrastructure and software services in an easy self-serve manner. As they create platforms as a service, that team doesn’t need a lot of domain specific knowledge. It only focuses on the technological aspect, makes it reproducible, and shares the solutions to all teams. This facilitating setup scales very well! My colleague
Ruurtjan Pul shows in this blog how scaling can be achieved from a team composition perspective. There is however one big risk: Taking a waterfall approach.
The data mesh approach tackles the difficulty of domain knowledge in relation to data reuse. This is done by moving the responsibility of the data to the teams that produce and work with that data. Instead of a central team owning all the data, we now need a central team to facilitate all teams in managing their data.
A pitfall is to take a waterfall approach in getting this central team up and running. Don’t start by creating all required infrastructure and services, before you onboard the teams. As long as there is not a single team using the services, there is no added value. Thus you need to grow and improve the services iteratively, while teams can already use it.
A second risk is to have the platform as a service team dictate the way of working. This will make the team a bottleneck to the whole company. In an agile and iterative approach, some teams will need new tools or services which aren’t yet production ready for company wide adoption. Instead of limiting those early adopters, the platform as a service team should allow and empower discovery and trials of new tools and services. Let them empower the product teams and join forces. This will give both teams the experience needed to share the tools and services further across the company.
Is it possible to transition to a data mesh? Is it possible to have something in between a central data platform and a data mesh? How can we pragmatically take the first steps? Where we reap as much benefits as soon as possible. In a solution that is tailored to your organization’s infrastructure capabilities. The remainder of this post will explain how you can transition towards a data platform that enables machine learning solutions, empowers data scientists, and shares the internal way of working.
The first step: a lightweight central data platform
What is the first step you can take in creating that data platform? Unfortunately there isn’t a cookie cutter template. The approach should depend on the specific situation, including the existing tech stack, available skills & capabilities, processes and general DevOps and MLOps maturity. I can give you generic advise, which hopefully gives a useful perspecive.
One approach is to combine the benefits of the previous versions as a stepping stone to a future, more advanced version (like the Data Mesh):
- Data engineers focus on extract & load, with minimal transformations.
- The domain specific (data science) teams focus on the advanced transformations.
- Tooling should be made available to empower the teams.
That approach is to create a lightweight central data platform, and consists of the following steps:
- Take one data science team with a specific use case.
- Setup a team, consisting of both platform engineers and data engineers.
- The platform engineers provide the data science team with an analytics environment, containing at least storage & processing.
- The data engineers load the raw data from the source tables, add basic standardization transformations, and provide it to the use case team. Together with the platform engineers, they create the required services to do so.
- The data scientists collaborate with the data platform engineers to become self sufficient in scheduling, running and operating their data transformations, model training loops and model serving. They collaborate with the data engineers to professionalize their data transformations.
In this case, the data scientists still have to do a lot of data mangling. However, instead of presuming that doesn’t happen, we accept it, and provide them the tools to do their work optimally.
A key aspect of this approach is to start with a focus on one use case. Data engineers, platform engineers and data scientists all solve this one case first. In the meantime, they get experience in developing the necessary tools to scale up later.
The result is as follows:
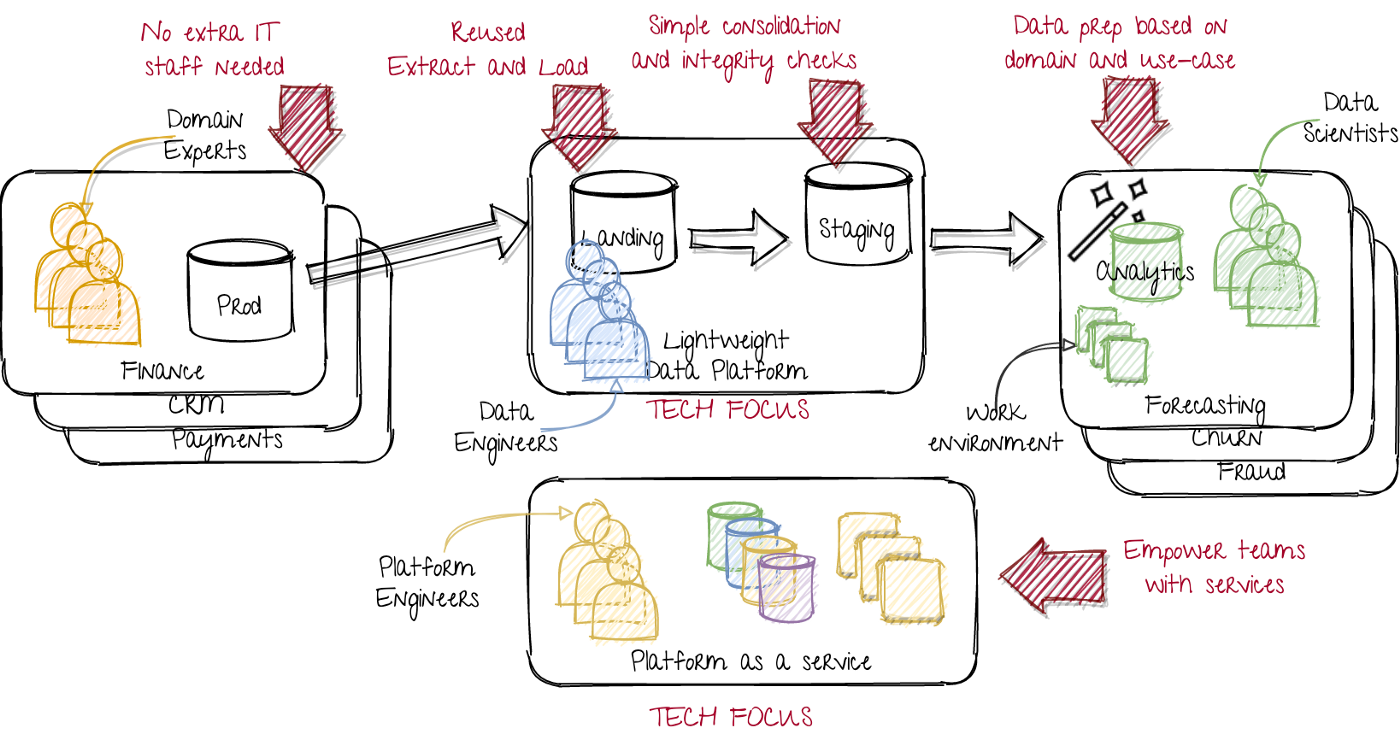
A lightweight data platform, as a step toward the data mesh. Image by author.
On the left, we keep the original situation, where the departments or product teams just develop or operate their production instances. This limits company wide changes.
In the middle, the data engineers focus on lightweight data modelling with high quality pipelines. They mainly work on loading al the data, and providing standardized methods of access. They have a strong tech focus, including infrastructure and services.
On the right, the data science teams focus on creating the data product, based on all the required domain knowledge. They obtain said domain knowledge by learning from their customers (the ones using their data product) and the teams of upstream data sources. They run all the required analytics and transformations, while being supported by the platform as a service team. They have a strong domain and use case focus.
At the bottom, the platform as a service team works on creating reusable components. They thus have a tech focus. They serve the data science teams, who have a domain focus. The platform as a service team should be driven by their requirements.
The next step: scaling and sharing across teams
The next step is to scale up. Scaling can be done on various dimensions, including getting more source data-sets, on-boarding more data science teams, or adding more empowering platforms as a service (think feature stores, model serving, and so on). Again, these choices depend on the circumstances.
For now, let’s take a typical step: on-boarding more data science teams. On-boarding the first team ensured the developed services are useful. The first team was the launching customer. The platform as a service team has ensured good market fit to internal customers. The next team should get up and running faster and more smoothly.
With multiple teams using the services, the next hurdle will be to allow sharing data between the data science teams. This probably requires some changes in services and the way of working. But if that milestone is reached, the platform initiative will really improve the lives of all the subsequent teams. This results in the following situation:
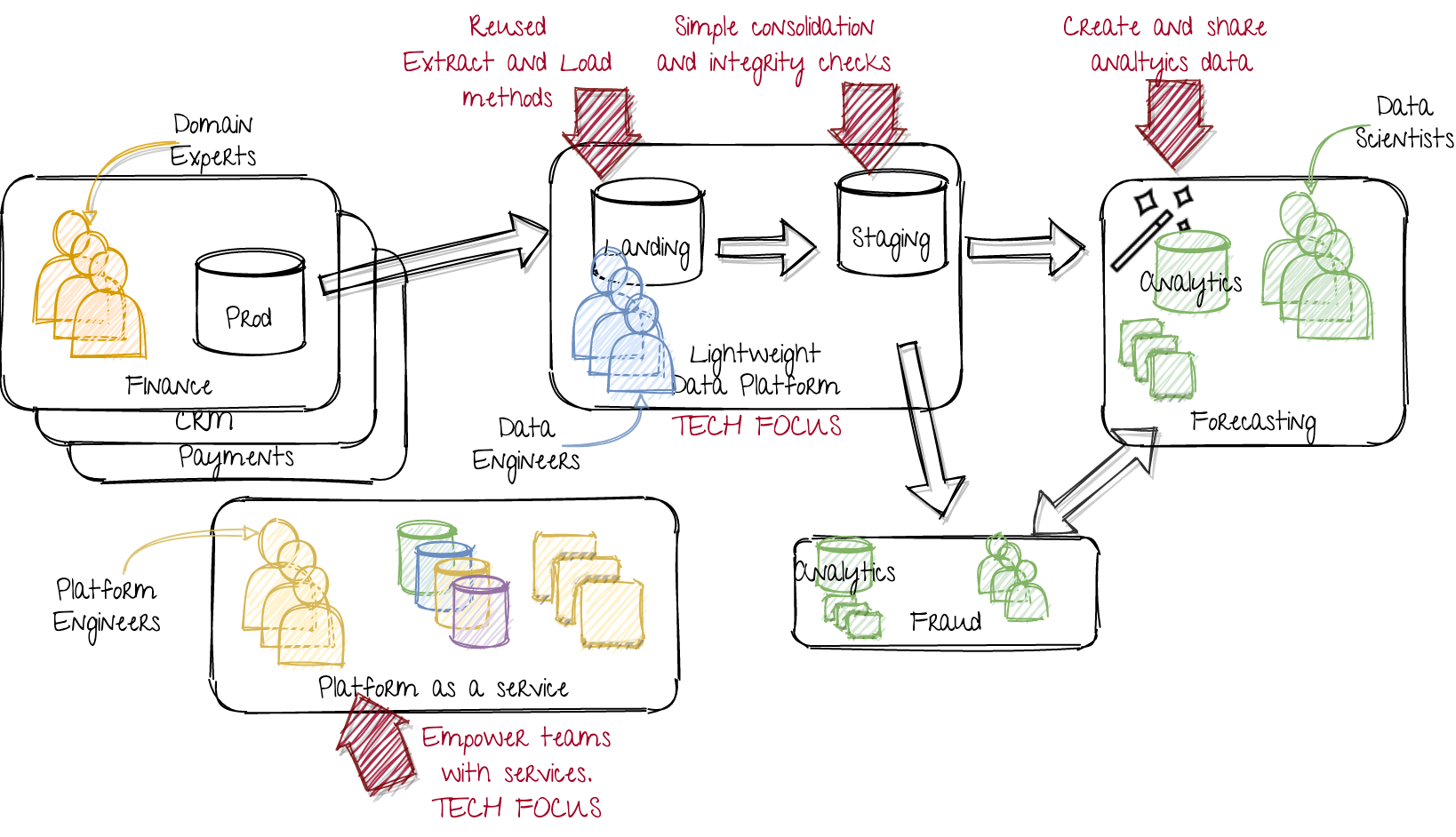
Scaling up by on-boarding more teams
Compared to the previous image, we now have an extra data science team, developing a fraud detection product. They should be able to reuse developed services from the platform engineers and reuse the data from the first forecasting team.
Following steps: professionalizing and scaling
Don’t forget the goal of these data platform initiatives. The goal was to enable more data products. Therefore, besides on-boarding multiple data science teams, it’s important to work towards models in production. Empower the first (few) teams to actually embed their model predictions into the business.
With these platforms, processes and way of working in place, the next step is less clear. There are a lot of opportunities to improve the service qualities and team collaboration.
The quality of the provided services could be improved, depending on what the business needs. Perhaps a real-time feature store is needed, a new model serving platform, auto-ML tooling, or better model monitoring?
In terms of alignment of teams, probably some shifts will need to be made. Perhaps a lot of cases require a ‘customer 360 view’, which might result in creating a team to manage that consolidated view, with some auto generated features. Various similar common problems can be used as initiative to create new common solutions.
Wrap-up
I’ve shown one way of moving towards a more data driven organization, by taking an agile approach to its development. Instead of proposing any solution as “the best way”, this post is hopefully an extra perspective to compare your situation with.
Key components of this approach are:
- Agile (internal) customer focused approach.
- Platform thinking.
- Removing bottlenecks, while providing a platform that is flexible and empowers the data science teams.
- Self sufficient teams, with freedom and autonomy. They are free to use the services that suits them and can autonomously prepare their data.
If you have any comments, or lessons learned to share, please leave me a message.