Staying in control of your IAM model
Visualise and query your cloud resource permissions using Mia
tldr; staying in control of your IAM model is hard, especially when it evolves over time. That is why we built and open sourced Mia. It helps you visualize, explore and query your AWS IAM and Postgres IAM model.

Every major cloud provider offers an Identity and Access Management (IAM) suite that gives you tremendous powers to control what your resources and users are allowed to do. This is great, especially when dealing with sensitive data. You’re free to create IAM roles and policies tailored towards specific use cases.
On top of this, many managed services such as AWS RDS or Azure SQL Database provide integration between the cloud IAM system and the managed service internal IAM system (e.g. Postgres roles and grants). It allows you to authenticate against your cloud provider and get authorized on the service level using that cloud based identity. As an example, consider your serverless function that uses its attached IAM role to connect to a Postgres database. No more injecting credentials at runtime.
Having these options and integrations is wonderful, but they also provide some challenges:
- Explainability in a growing IAM model: in many cases your cloud provider account will host many different IT components. Understanding the interaction between all these components from an IAM perspective becomes non-linearly harder when the number of components grows.
- Auditability: seemingly simple questions can be hard to answer. Take the “which users have access to bucket X?” question for example. In a cloud IAM world, you tend to reason from IAM resource (role, user, policy etc) to cloud resource (VM, bucket, message queue, etc). The other way around is non-trivial.
To illustrate how these challenges emerge when your IAM model grows, let’s have a look at the setup of one of our clients.
An example: a data platform on AWS
At one of our clients, a financial budgeting app, we helped create a data platform on AWS. By using a combination of AWS services like Glue, Sagemaker, S3, Lambda and Athena, our users can create analyses, experiments and deploy AI models.
Naturally, the platform is composed of many components. In our case, we have defined a component as a set of resources that together facilitate serving or consuming a data set. Examples of such components are:
- An ingest pipeline of clickstream data;
- A machine learning model (pre-processing, training and inference) pipeline;
- A Lambda function importing data from an external data provider;
- Common infrastructure such as central buckets, VPC’s and IAM roles and policies.
A data platform component may be composed of many AWS resources itself. If we look at the ingest pipeline for example, we would see that this consists of a landing zone S3 bucket, a Glue job and some Cloudwatch and IAM resources. The target bucket would be part of the common infrastructure component.
Infrastructure design approach
While building the platform, we adhere to the following infrastructure design principles relevant to IAM:
- Everything is code such that we have a four-eye principle and an audit trail in Git (which we don’t have administrator access to).
- Every resource (Glue job, Lambda, etc.) should have its own IAM role whenever possible. This way, we can easily remove a component without affecting others, or leaving orphaned IAM resources behind.
- We use
ActionandResourceexpressions exclusively in an IAM statement unless we have very good reason to do otherwise. We don’t like theNot<Resource|Action>version of these expressions because they invert the deny-by-default nature of IAM and thus go against the principle of least privilege.
In making our lives a bit easier, we use Terraform to cover the “everything as code” principle. Every data platform component, that roughly maps to one repository, contains a bit of Terraform code to setup the required infrastructure. Doing this also directly covers our second principle: enabling or disabling a data platform component is just a matter of applying or destroying that component’s Terraform code.
Because many components consist of the same resources such as Glue jobs and Lambda functions, we have created our own Terraform modules that abstract away some of the repetitive tasks like creating Cloudwatch log groups, alerts, IAM roles and policies. While this is great (we automated tedious work!) this is also the point where things are becoming harder to grasp. As the number of platform components is growing, so do the number of IAM resources.
IAM management challenges in practice
A growing number of IAM resources is where the first IAM management challenge emerges: yes, we have a four-eye principle but that will always implicitly be in the context of that specific component. Detecting whether a change in component A also affects component B is not always directly visible.
An obvious example of where this could cause trouble is updating a managed policy in the common-infrastructure component. It can be expected that this policy is being used by many other components, because it helps prevent writing the same policy statements over and over. The challenge here is to safely adjust this policy without unexpected side effects.
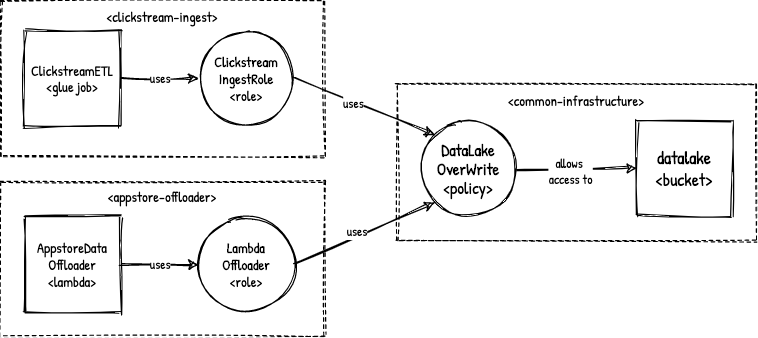
Updating the DataLakeOverWrite policy should be done with care.
The second IAM management challenge has presented itself a while back at this client with the following requirement: they wanted to offer their services to other businesses, meaning there was a need for multi-tenancy on a data access level. While before there was only bucket data, we now also have bucket data-client-a and data-client-b. A data scientist who is running a notebook that reads from bucket data is not allowed to read from data-client-a from within the same notebook. So, roles that can read data from buckets of sort data should be mutually exclusive and we need to show that in an audit. When you know which role(s) to show and check, this is fairly easy to verify in IAM. However, reasoning from a bucket perspective in this case is not possible; it would require you to rephrase the query and do an exhaustive search from the IAM perspective. If you don’t run these checks, you leave the risk of allowing unwanted allow links to exist in your IAM model. In the picture below, consider the DSInternalNotebook role that you may have created a year ago before the multi-tenancy requirement existed. At the time, a wildcard * may have seemed to make sense. If this wildcard has not been setup in exactly the right position, it will have consequences in a multi-tenancy setting.
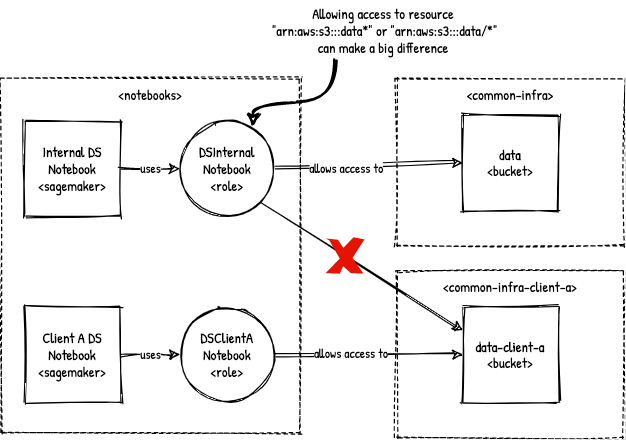
A wildcard (*) that is not exactly the right position can make a big difference.
We haven’t found a way to deal with these challenges in our daily workflow yet. Yes, we have experimented with keeping all infrastructure code in a monorepo but that didn’t solve the actual problem besides narrowing down the search space to only one folder.
Mia
Of course, the whole point of this blog post is to also offer a part of the solution to the posed problems. Mia is a small application (or rather a large script) that crawls (IAM) resources and rearranges them into a graph that let’s you:
- Reason from a resource perspective: answering “which roles have access to bucket
dataanddata-client-a?” becomes trivial. You take the buckets as the starting point and find paths to all users.
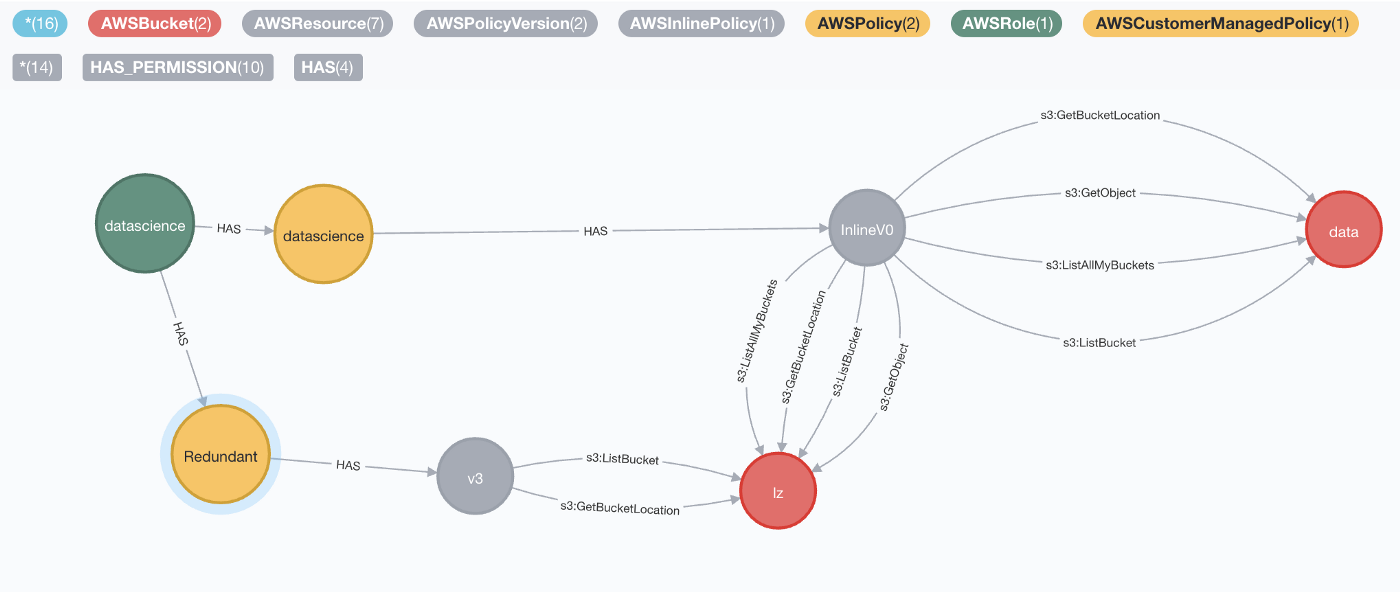
The datascience role has a policy that provides redundant permissions
2. Interconnect IAM models of different systems: let’s say you have a RDS Postgres database that also allows you to login using some AWS IAM role. When you want to know which AWS IAM roles allow access to table Y, you take table Yand find all paths to connected AWS IAM roles. This will not only tell you that you’re able to connect, but also tell you that you’re allowed to do a SELECT only and not an INSERT.
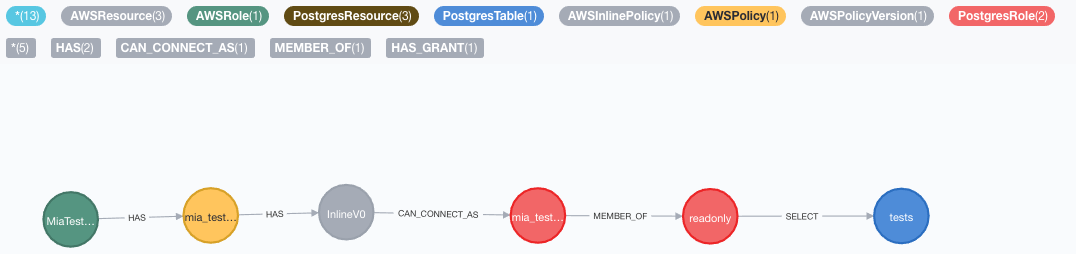
Cypher query: MATCH p=(:AWSRole)-[*]->(:PostgresTable) RETURN p
3. Query IAM language expressions on a global level: in the example, we have shown that we have some team restrictions on the use of NotAction and NotResource expressions in IAM Policy statements. To verify and enforce this beyond Git, you’d have to crawl all installed IAM Policy statements. Mia is doing exactly this so now you can just run a query to verify.
Mia is able to offer answers to such graph queries because it is using Neo4j. In fact, when you’re using Mia, you’re just writing Neo4j Cypher queries. A great way to start exploring is by using the Neo4j web interface. The screenshots included above are from the web interface.
In the project we described in the example, we have used Mia on several occasions. When we’re not sure about possible interference, we might deploy a change to the acceptance environment and use Mia to visualize the effects. We have also used Mia to help us find the last IAM Policy statements that were still using expressions we don’t like anymore.
One thing that we should emphasize is that Mia is not an IAM simulator. It’s merely a way to present resources and their relations in such a way that understanding your IAM model becomes easier. When you write the right queries, you can come a long way though. For a list of caveats, please refer to the repository.
If you think this is interesting, we also recommend exploring complementary tools like CloudMapper and CloudTracker.
At the time of writing, Mia supports loading AWS IAM and Postgres auth into an interconnected data model. So, if you’re using either AWS, Postgres or both you can give it a try by checking out the repository here!