
Machine learning models on AWS with the Rendezvous architecture
tl;dr Testing and updating machine learning models can be done safely and systematically using the Rendezvous architecture. This architecture lets you run multiple model versions in parallel, by decoupling them with the message queue SQS and streaming platform Kinesis. A rendezvous function is responsible for selecting the model result with the highest relevance. Although the Rendezvous architecture is relatively easy to implement, defining the input/output structure of the models can be tricky. The input/output structure is the contract between models and the rendezvous function, but new model versions may need different information and therefore complicate the contract.
How to create a serverless deployment with Lambda, SNS, SQS and Kinesis
In the book Machine Learning Logistics, Ted Dunning and Ellen Friedman describe what they call the “Rendezvous architecture”. The concept is relevant, because more and more companies are looking to mature their model deployment architecture. To understand the concept better, I created a minimal implementation on AWS, and share my experiences here. This blog covers the logical flow of the Rendezvous architecture, a serverless implementation, scalability issues, Terraform setup and the data model that is communicated between the different components.
This blog describes my interpretation of the architecture, which may deviate from the book’s description. In particular, I use serverless and managed services available on AWS instead of container based microservices. The minimal example is implemented using Terraform and Python, and is available on GitHub. Since I needed some models to run, I used a RandomForestRegressor with the Boston housing prices case.
Goal of the architecture
The Rendezvous architecture tries to resolve the following problem: You want to deploy (machine learning) models and have the ability to evolve your models. This requires meeting service level agreements at all times, while enabling new model versions in a realistic setting. The architecture solves this by not choosing which model should be run, but executes all the models at the same time, and selects the best result.
Workflow
A request for model evaluation follows the following steps through the architecture (Figure 1, taken from Machine Learning Logistics):
- Request comes in at the Input block
- The Input block gathers context data from databases etc.
- All models are run in parallel using data from the input block
- The models publish their results to a stream
- The rendezvous function collects and chooses which results to return. This choice can be made based on model version, latency or other criteria.
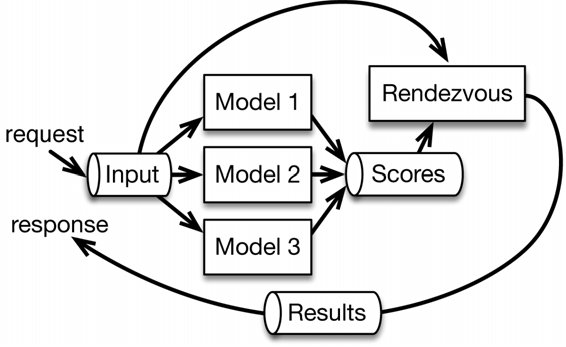
Figure 1: Rendezvous architecture as described in Machine Learning Logistics. The models are evaluated in parallel and place their result on a stream. Results are then collected from this stream and the best result is used.
Rendezvous on AWS
The book Machine Learning Logistics does not specify which streaming tools to use in each step, outside MapR Streams framework. I chose the following AWS services to set up the architecture:
- API Gateway: Managed/serverless REST API that implements endpoints and can trigger a Lambda function
- AWS Lambda: Serverless function that lets you execute code without setting up servers
- Simple Notification Service (SNS): Messaging service
- Simple Queue Service (SQS): Fully managed queueing service
- AWS Kinesis: Fully managed data streaming service
- AWS Firehose: Delivers streaming data to other services like S3
- AWS S3: Object storage
I set off to implement this architecture on AWS, and came up with the following configuration:
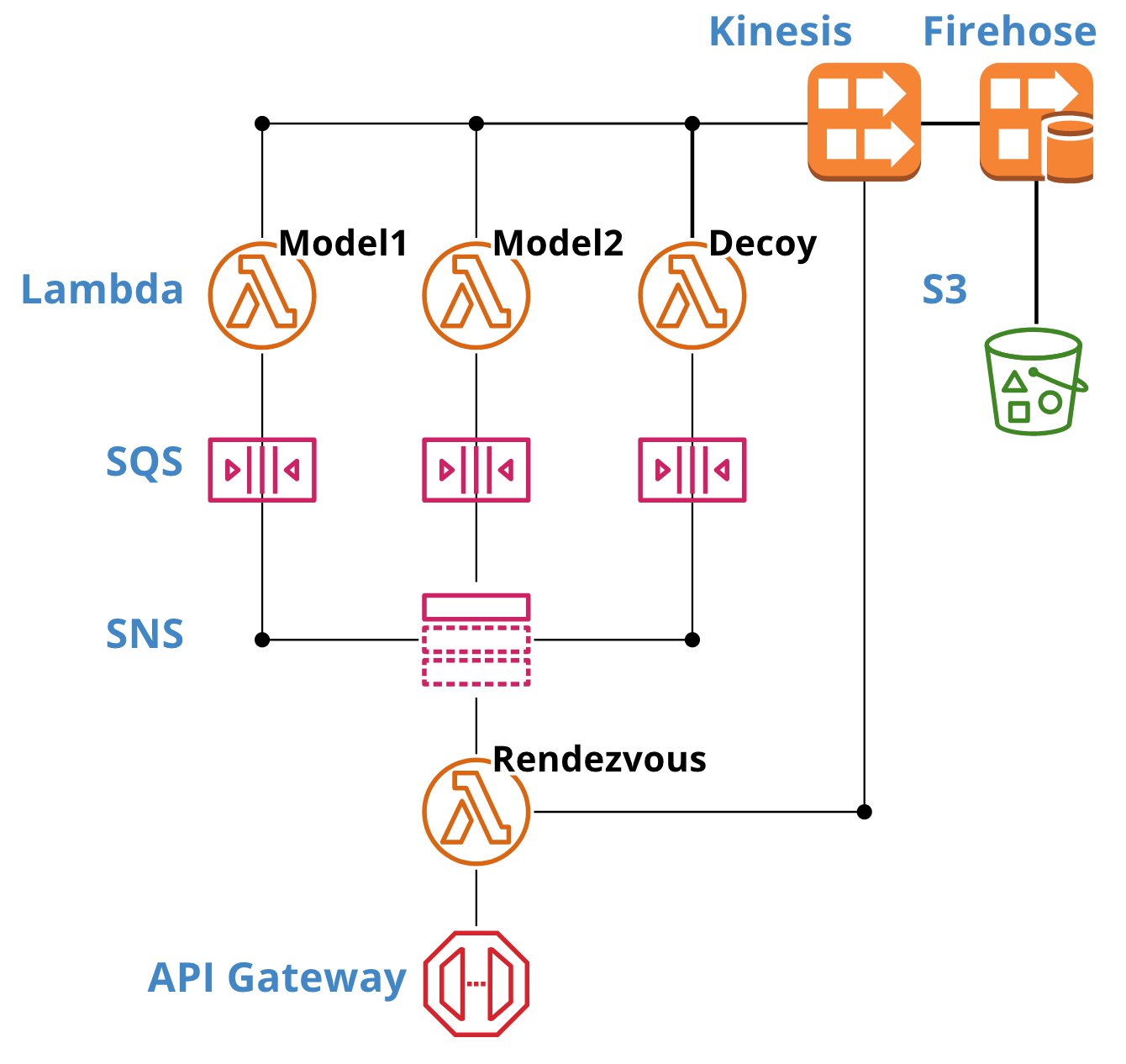
Figure 2: An implementation of the Rendezvous architecture using managed and serverless AWS components. Code is available on GitHub. Figure made with cloudcraft.co.
On AWS the following steps represent my Rendezvous architecture implementation:
- The HTTP post-request is sent to the API Gateway endpoint. The body contains the parameters (features) for which the user wants the models to run.
- The API Gateway invokes a Lambda function that runs the rendezvous function.
- A unique identifier and context data are added to the request and the rendezvous function publishes a message to an SNS topic.
- SNS automatically sends the request to all subscribed SQS queues.
- Each SQS queue invokes a Lambda function.
- Each Lambda function runs a model. In Figure 2 these are decoy, model1 and model2. Model1 and model2 may be different versions of the same model. The decoy model only forwards the incoming data from the SQS queue to allow for monitoring and debugging.
- When a model is done it publishes a message to a Kinesis stream. That message contains the unique identifier of the request and the model results. AWS Firehose writes messages on the stream to S3 for later analysis.
- The rendezvous function monitors the Kinesis stream and collects the results that contains the unique request identifier.
- Then, the rendezvous function chooses which result to return to the API Gateway. The choice can be made based on version number, priority or a different criterion.
Rendezvous function
The rendezvous function contains the logic needed to operate the system. It has the responsibilities of creating an appropriate message that contains all information needed by the models. The rendezvous function collects the results from the Kinesis stream, keeping in mind the number of deployed models, and the maximum time that the models have to publish results. Models that take to long to publish their results are ignored.
Scalable services
Choosing serverless and managed services reduces implementation and maintenance efforts. Also, it helps to create a scalable design from the start of a project. In this case, scalable means that an increase in the rate of model runs per second, as well as an increase in the number of models does not require any intervention in the architecture or the code in the rendezvous function.
Although the used services have the capability to scale up, I would say that the current implementation only partially achieves scalability due to Kinesis. API Gateway, SNS, SQS and Lambda have high service quotas, and have basically no limitations. The current configuration allows for thousands of requests per second.
Kinesis scalability consideration
To determine the needed Kinesis capacity, you must balance the reserved capacity against the costs. The rate at which records can be extracted from a stream depends on the number of reserved shards. One stream can be queried five times per second per shard. Shards are paid per hour ($0.015/hr), over-provisioning shards is therefore expensive. If you need low latency in the Rendezvous architecture, the stream must be checked frequently for new messages.
These Kinesis-specific issues can be addressed technically, which is mostly in finding balances for the two mentioned issues. Possibly a solution could even be found in using a database or S3 over a pub/sub service, but the debate about these two concepts is out of scope for this blog.
Decoupling and Terraform
One of the benefits that the Rendezvous architecture brings is the ease of deploying new models to AWS without disturbing existing deployments. In Terraform, code can be reused by creating a module. I created a module that implements a new Lambda function with corresponding Python code. When the module is called, models are automatically registered with SNS and discovered by the rendezvous function. The directory structure for the module and python/ directory are shown in Snippet 1. Terraform code to add a new model is in Snippet 2.
A new model is added by creating a directory in python/ that contains a file called lambda_function.py and a function named handler(sqs_event, _) (this is the AWS Lambda handler). The Terraform code needs to call the model and sqs modules. The model module will create a new Lambda function with the corresponding Python code and IAM role. The sqs module creates a new SQS queue that subscribes it to the SNS topic, the new SQS queue will invoke the Lambda function. With this configuration, a new message that is submitted to the SNS topic is automatically routed to the Lambda function.
Snippet 1: Terraform module that deploys a new model.
Snippet 2: Adding a new model to the Rendezvous architecture.
Data model
The architecture can only work if at least the following information is present in the JSONs that are sent to the models:
- Which Kinesis stream to publish to (
kinesis_stream) - The unique request identifier (
uuid) - The parameters that are needed to execute the model (
data)
Snippet 3: These fields are sent from the rendezvous function to the models. The RendezvousMessage class is shared between Lambdas to enable validation.
The RendezvousMessage class is shared between both the rendezvous function and the models. It is important to share this data structure to allow for data validation. Sharing of the Python code between Lambda functions is done via a Lambda Layer.
A likely scenario where new model versions require additional information is not covered in this setup. Such a scenario would see different Specifications implementations for different models. The book does not provide a clear guidance on how to implement different input data for different model versions.
For example, a new model version may need additional external data from a database. For now, adding another block (Lambda function and SQS queue) before the rendezvous function would be an option. This solution would propagate all external data to all running models, which may be undesirable since it pollutes the data stream with unnecessary information.
Model Response Structure
The structure of the model result (Snippet 4) from the model is defined to serve as a contract between models and rendezvous function. It is important to have such a structure so that it’s clear what fields are required when implementing a new model. In this example, fields contain the test, train score and the model result price. Model version can be part of the ModelResult as well. The ModelResponse is filled with metadata like the unique request identifier, some metadata about the duration of the model run, etc. In case of an exception, the ModelResult can be replaced by a ModelError class that contains debugging information.
Snippet 4: Classes that are the template for a result that is published to Kinesis. ModelResponse: metadata about the model and the request. ModelResult: results like the price and the model score.
Business Logic
Even though I tried to keep the architecture implementation as generic as possible, business logic is inevitably present in the data models. In the current setup, business logic is confined to the ModelResult class by the price field. In a real life example, the ModelResult class would contain much more information. The contents of the ModelResult must be communicated, for example through documentation of the API Gateway endpoint. This is important since the caller of the API Gateway endpoint needs to rely on certain information to be present in the response.
Conclusions
The Rendezvous architecture (from Machine Learning Logistics) provides a flexible way of deploying machine learning models on a cloud environment. Key elements of the architecture are running multiple models in parallel, and deploying new models with only minor intervention in the architecture. The models, running in parallel, publish their result under a unique identifier to a Kinesis stream, from where they can be collected using the identifier.
For implementation on AWS I relied on serverless and managed services in order to create a scalable and low maintenance setup. This involved API Gateway, SNS, SQS, Lambda and Kinesis. New models can be deployed by simply creating a new SQS queue and a Lambda function, which will automatically run when the SQS queue is registered at an SNS topic. The Kinesis service requires optimization if it was used in a real world scenario, due to the fixed costs of the shards, and the limited rate at which results can be extracted from a stream.
When implementing the architecture in a real case, one should take time to design a good data model. The data model is needed to synchronize and validate input and output for the models and the rendezvous model. Evolving the data model is particularly tricky when new model versions require different input data.