
Architecting a workable, yet secure data exploration environment on the Google Cloud Platform
Having worked for multiple major organisations in the Netherlands, there's always this recurring topic: how to give data scientists as much freedom as possible for exploring data, while minimising the amount of data leaking out of the platform? There's a plethora of books you could write on this topic in general. This post focuses on a network architecture that minimises data leakage out of the Google Cloud Platform (GCP), while maintaining a workable environment for data scientists.
Situation
The data scientist:
- Mustn't download data onto the disk of their own physical machine.
- Uses Jupyter Lab through AI Platform Notebooks.
- Submits jobs to BigQuery and Dataproc while developing in the IDE installed on their machine.
- Works with highly sensitive data.
- Needs logs to be available for debugging.
The organisation requires that:
- All data must be transferred securely.
- There is a separate GCP project for each model.
- There are shared data projects.
- Data access is controlled on service account level.
- Costs of a model must be transparent.
Proposed architecture
The first important component for the proposed architecture is the Virtual Private Cloud (VPC): all components within the cloud run within it — even the Google Cloud services. By setting up this perimeter, it becomes possible to set up firewall rules and policies without replication.
Cloud VPN must be configured to keep appropriate (audit) logs and metrics. With the right alerts, actions can be taken on suspicious behaviour going over that connection. The level of detail in those logs is, however, limited. For larger organisations, a Cloud Access Security Broker (CASB) would be a solution to consider. It allows enforcing stricter security policies on the connection between the organisation and GCP. As an example, specific URL patterns can be blocked.
A user can join the VPC through Cloud VPN. Once connected, Cloud IAM is the next security layer. Users are provided with a Jupyter Lab web UI, which is the preferred way of working. The only Cloud IAM role they have, allows them to control their personal AI Platform Notebook instance. This instance runs with a service account linked to the specific model that's being developed.
The service account is granted access to data and resources. Any API call made from the Notebook instance is authenticated with those credentials. This method has the advantage that users can't access any data from their local machine using personal credentials. However, they can call APIs that do have access to data. In that way, a job can be submitted to Dataproc or BigQuery from the IDE.
Be aware that the Google Cloud services must also become part of the VPC. Therefore, VPC Service Controls need to be set up for Dataproc, BigQuery, and Cloud Storage. They then reside within the same VPC as the Jupyter Lab interface.
Data is stored in multiple shared data projects. The data is, as such, decentralised and each data owner has the responsibility of managing and providing their data. Access to the data is controlled on table level in BigQuery or object-level in Cloud Storage in each of those projects. Data sources there are read-only for the model service account. This leads to transparent model cost, as all data processed for a data science model is billed in its own project.
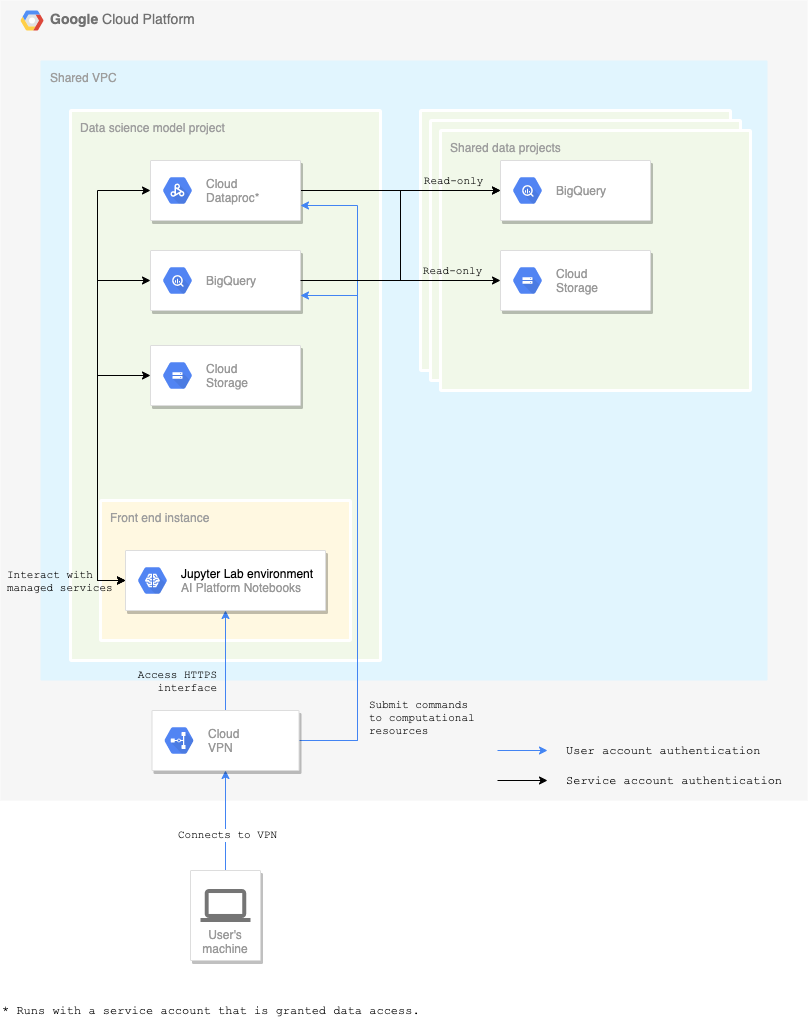
Architectural drawing of the data exploration platform.
Risks
Even with the solution as described above, there are still risks:
- Upon writing, it's not yet possible to entirely disable the Download button in Jupyter Lab. Although there is a workaround to disable it by default, audit logging and alerting must be set up for a malevolent user who reverts that change. The workaround would only prevent accidental downloads.
- Copying of data from the BigQuery UI, allowing the user to copy a (limited) number of rows.
- Copying of data from the Jupyter Lab UI and possibly automating that process in the browser can be mitigated in the same way as in the previous point: by setting up alerts based on Cloud VPN metrics and logs.
It’s up to the organisation to decide whether measures against these are sufficient or even required. The first two of the risks below can be contained using CASB, but the question is whether setting that up is worth the effort.
Concluding remarks
- Little maintenance is required in the proposed architecture, as mostly fully managed services are used. In case you would choose to add a security layer such as a bastion host, resource and maintenance cost increase significantly.
- In reality, there’s no way to prevent data leaking out of the platform entirely. Compromises must always be made on security, cost, usability, vendor-specificity, etc. Even if you’d argue there’s a way to technically prevent it, in the end data stored in the human memory — although limited — remains a risk factor.
- Setting up the right monitoring and alerts is key in securing the data. This is possible because a VPN connection is required to connect to any GCP service.
- To take it to the next level, (enterprise) organisations could implement a Cloud Access Security Broker (CASB). This allows enforcing stricter security policies on the connection between the organisation and GCP. As an example, specific URL patterns can be blocked.